[](){}();
Immediately applied lambdas in C++
Recently I had the opportunity to write a multi-threaded histogram generator for my high performance computing (HPC) class at university. The assignment was the first time I’d completed a “larger” project since finding my way around the Flux project. When attempting to contribute to Flux, something I found interesting was the use of “immediately applied lambdas”. This is the idiom where a variable is assigned to the output of a lambda function that is immediately invoked, thus resulting in the variable being assigned a value as opposed to a closure type.
1
2
3
4
5
auto x = [](){
return 0;
}(); // immediately call the lambda to return a value.
assert(x == 0);
The above is possibly the simplest example of an immediately applied lambda, with x
simply being assigned to 0 through it. For such a trivial use it’s definitely not
good practice to use an immediately applied lambda, but we’ll build out some more
concrete examples in the future. For an example in Flux, take a look at
line 113 of the flatten adaptor.
Why?
Based on the example above, using this “trick” seems to be a very verbose and confusing method to assign variables. However, I think that using immediately applied lambdas leads to code that easier to reason about, understand, and refactor. While I don’t yet have any experience working on industrial scale codebases, I still feel the pain of going back to an old project that I didn’t document and trying to parse the code that I previously wrote. I think that using this idiom makes that process less painful, and through the power of constant expressions and optimization there is little if any performance penalty.
The Syntax
The syntax for creating an immediately applied lambda is simple. Simply call the lambda
using the () operator immediately after the lambda’s closing bracket. The example below
shows the difference between creating a closure object and creating a value by immediately
calling the lambda.
1
2
auto closure = [](){ /*...*/ };
auto value = [](){ /*...*/ }();
An Example
When working on my histogram generator I needed a way to break down a input of randomly
generated floating point numbers (simulating real data) into different slices for each
thread to operate on. To do this I used std::span to wrap the input data, and then used
.subspan() to get the slice for each thread.
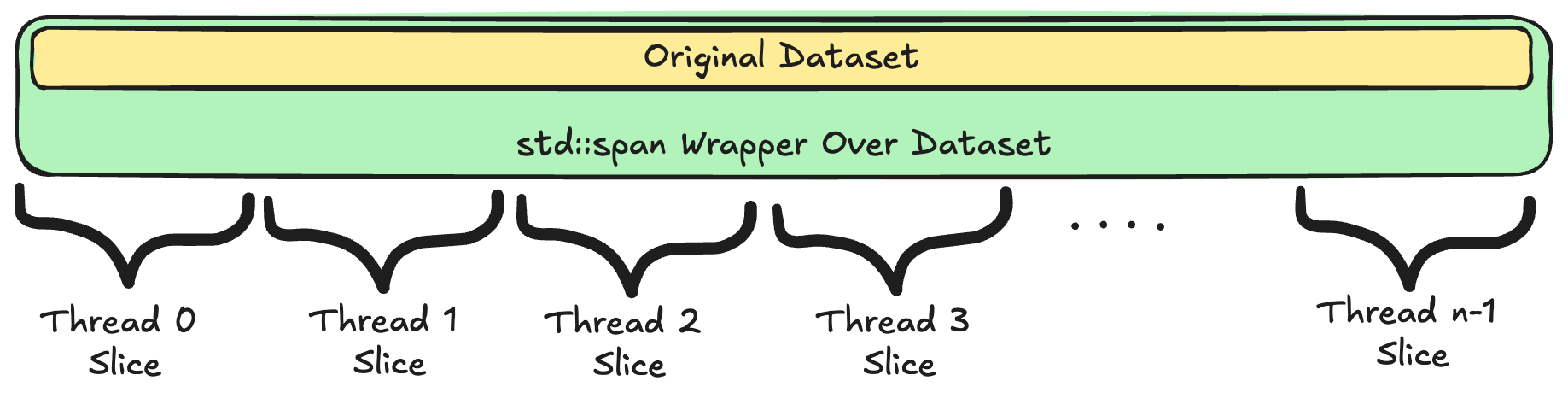
It’s important that every element in the original dataset is
- eventually assigned to a thread, and
- no element is assigned to two threads.
If either of those properties are violated, then we’ll have either the case where the histogram did not accurately count all the elements in the input dataset, or that an element was counted twice. Both lead to incorrect results.
Since the dataset size and number of threads have to be determined at runtime for this assignment (according to the assignment description), we’ll have to calculate the slices for each thread at runtime. My first attempt at doing so worked successfully like this:
1
2
3
4
5
6
7
8
9
10
11
auto thread_func(
int thread_id,
int number_threads,
const std::span<float> dataset) -> void
{
const auto slice_size = dataset.size() / number_threads;
const auto slice_starting_index = thread_id * slice_size;
const auto dataset_slice
= dataset.subspan(slice_starting_index, slice_size);
}
The thread_id corresponds to which thread is currently operating on the data, and is
assigned by me when the threads are created and ranges from 0 to n-1, where n is
the desired number of threads. Looking over this code it should not be hard to convince
yourself that in general, dataset_slice will be a subspan over the elements that the
current thread is to operate on.
However, this function has a flaw. What if the datasize is not easily divisible by the number of threads. For example, what if you have three threads, and 11 elements?
Using our function, we’ll generate three dataset slices, one for each thread. The table below tells us what the corresponding starting index and size of each slice will be:
| Thread ID | Slice Size | Slice Starting Index | Slice Range |
|---|---|---|---|
| 0 | 3 | 0 | [0:2] |
| 1 | 3 | 3 | [3:5] |
| 2 | 3 | 6 | [6:8] |
Immediately, the issue becomes clear. Elements 9 and 10 will not be accessed by any thread, as the last subspan assigned (to thread 2) is the elements from 6 to 8. Clearly this algorithm for splitting up work is not correct, because we are not calculating the histogram from all of the input data.
An easy way to fix this algorithm would be to just have the last slice cover all of the remaining data. That way, the last thread may do more work but all of the data will be covered.
| Thread ID | Slice Size | Slice Starting Index | Slice Range |
|---|---|---|---|
| 0 | 3 | 0 | [0:2] |
| 1 | 3 | 3 | [3:5] |
| 2 | 3 | 6 | [6:10] |
For this assignment it was reasonable to assume that the datasize would be much larger
than the number of threads (e.g. 10’000’000’000 elements vs. 16 threads), so it wouldn’t
be an issue if one thread processed at most n-1 more elements than the other threads.
The design decision I made was to have the last thread process all of the remaining
elements.
Now thread two is processing elements 6 through 10, and no elements are missed.
Now we run into the issue of changing our code. A simple refactoring results in something like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
auto thread_func(
int thread_id,
int number_threads,
const std::span<float> dataset) -> void
{
const auto slice_size = dataset.size() / number_threads;
const auto slice_starting_index = thread_id * slice_size;
std::span<float> dataset_slice;
if (thread_id == number_threads - 1) {
dataset_slice
= dataset.subspan(slice_starting_index, slice_size);
} else {
dataset_slice
= dataset.subspan(slice_starting_index);
}
}
Calling
.subspan()without a size just returns a span from the given index to the end of the input data.
To me, this looks messy. First, we lose the const specifier on
our dataset slice. While the code still compiles (at least on GCC 14 on compiler
explorer) it’s quite misleading as we definitely do not want the underlying data
changed. We annotated that by marking the input dataset span as const, so it feels
bad to get rid of it now.
Also, we lose the ability to use auto. While not the end of the world, there are
many reasons to use auto over explicitly declaring the type. Far smarter people than
me have given reasons, so to learn more about prefering auto I would check out
the following:
Finally, this code introduces a new if-statement to be analyzed when trying to determine
what the code is doing. It’s not immediately clear that this if-statement relates to
dataset_slice, and opens up the opportunity for more convoluted code to be created in
the future as other operations could be stuffed into the statement, further muddying the
waters.
By using an immediately applied lambda, we can solve these problems and more! Here’s the updated code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
auto thread_func(
int thread_id,
int number_threads,
const std::span<float> dataset) -> void
{
const auto slice_size = dataset.size() / number_threads;
const auto slice_starting_index = thread_id * slice_size;
const auto dataset_slice = [&](){
if (thread_id == number_threads - 1) {
return dataset.subspan(slice_starting_index, slice_size);
} else {
return dataset.subspan(slice_starting_index);
}
}();
}
In basically the same number of lines of code we have brought back the ability to use
auto, the const specifier, and we now have a clearly defined purpose for our
if-statement defined by the way we wrote the code. When reading this, (if you know about
immediately applied lambdas) it’s easy to see that, “Oh, this line of code gets the
slice of the dataset that applies to this thread”. All of the logic is in one location,
and it’s easy to reason about.
I’d argue as well that using this approach coupled with optimizations actually makes it possible for code to become even more readable as well. Consider the following small change:
1
2
3
4
5
6
7
8
9
const auto dataset_slice = [&](){
const auto max_thread_id = number_threads - 1;
if (thread_id == max_thread_id) {
return dataset.subspan(slice_starting_index, slice_size);
} else {
return dataset.subspan(slice_starting_index);
}
}();
This introduces a variable local to the lambda (inaccessible outside of it) that gives
meaning to the statement number_threads - 1. With optimizations this code will function
just the same as the code before, but now it’s more maintainable and clear as to what it’s
purpose is.
While there are other, likely more optimal ways to implement this functionality, we’ll end this example here as it has shown the general point.
Other Tips and Tricks
You can use this to initialize class members:
1
2
3
4
class X {
const y = [](){ /*...*/ }();
constexpr static x = [](){ /*...*/ }();
};
You can use this in statements:
1
while([]() -> bool { /*...*/ }()) /*...*/
You can use this in constant expressions:
1
2
3
4
5
6
const auto x = 10;
const auto y = [&](){
return 2*x;
}();
static_assert(y == 20);
You can also use this in template parameters:
1
2
template<size_t Size = [](){ return 0; }()>
auto x() -> Type;
The End
Overall, I think this is a great idiom to have in your toolbox, and it may come in handy more often than you think!